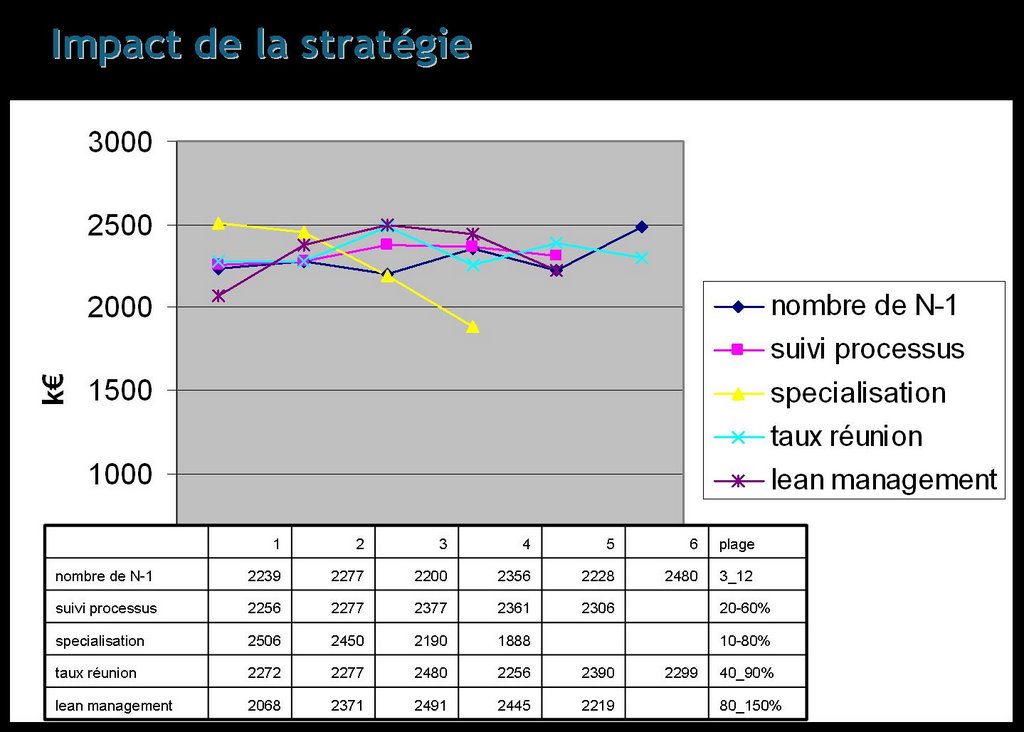
 La première slide montre le type de résultats que l'on obtient sur l'analyse simple des leviers stratégiques. Les résultats sont en k€, correspondant à la valeur produite par l'exécution des processus. Je reviendrai sur le type de données produite par la simulation lorsque j'aurais des résultats plus stables.
La première slide montre le type de résultats que l'on obtient sur l'analyse simple des leviers stratégiques. Les résultats sont en k€, correspondant à la valeur produite par l'exécution des processus. Je reviendrai sur le type de données produite par la simulation lorsque j'aurais des résultats plus stables.Ce qu'on peut retenir de ces premiers résultats:
- les leviers stratégiques ont un effet significatif sur la transmission d'information qui se voit sur les résultats économiques,
- l'optimisation est pertinente: il existe des optimum locaux
- Il reste du travail à faire pour produire des résultats convaincant d'un point de vue statistique !
Sur ce dernier point, j'évalue à un facteur mille l'augmentation de temps de calcul pour produire des expérimentations vraiment satisfaisante (cf. le message précédent)
En revanche, l'expérimentation avec les scénarios (ce qui permet de faire varier la charge de travail fournie à l'entreprise) produit des résultats logiques (plus il y a de charge, plus on crée de valeur), ce qui est une indication que le simulation est cohérente.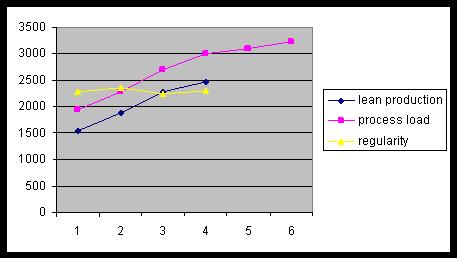
Il a fallu de gros efforts pour arriver là ! Un modèle un peu trop naïf d'ordonnancement produit facilement des résultats contre-intuitifs. En fait, la raison principale de la complexification du modèle SIFOA est la volonté d'obtenir un fonctionnement robuste de l'entreprise, qui repose sur une bonne réactivité et optimisation de l'allocation des ressources (agents & canaux).
Pour terminer ce message, je me suis amusé à simuler "un monde sans e-mail".
Ce type d’approche permet de donner une valeur (monétaire) au service de e-mail dans l’entreprise !
Dans cette première simulation, j'ai observé ce qui se passe si le canal email est remplacé par le courrier interne (essentiellement une augmentation de la latence):
- on observe 10% de baisse du revenu, ce qui est significatif (2045 vs 2277)
- Le canal ASYNC passe de 17% à 12%
- Augmentation répartie des autres canaux
Ce type de simulation est très encourageant. Nous avons une façon de trancher le débat entre les deux positions excessives que l'on entend souvent ("Le mail ne sert à rien d'un point de vue économique" ou "sans email aujourd'hui, l'entreprise s'arrête"). Notons que ce peut être les mêmes qui tiennent les deux sortes de propos, lorsqu'il faut payer la maintenance des serveurs dans le premier cas et lorsqu'il y a un virus dans le seconde cas :) La prochaine étape sera de simuler l'introduction du canal "instant messenging".
A suivre donc, avec une reprise à la fin de l'année.