1. Introduction
Au-delà de l’intérêt pour appliquer le Lean Startup et les différents principes de l’innovation digitale que je prônais depuis de nombreuses années (Bouygues et AXA), et au-delà même de l’excitation de vivre une expérience entrepreneuriale avec ma fille (une demi-douzaine d’influenceurs mais une seule designer et un seul codeur), l’application Knomee a été construite autour d’une conviction et promesse forte – self-tracking with sense – nourrie par nos expériences personnelles (j’en dirai un mot dans la section 4). Pour faire très court, le self-tracking est une excellente pratique (on le sait depuis plus de deux siècles), mais demande de la discipline. Dans le monde digital, une partie devient implicite, il suffit de porter une Apple Watch ou de posséder une balance Withings, mais il n’est pas forcément simple de lire ce que cachent les données, en termes d’hygiène de vie et de rapport couts/bénéfices des habitudes que nous cherchons à prendre en termes de santé et de bien-être.
Après un an de préparation et deux ans des développements de MVP successifs, il est apparu clairement que nous n’arrivions pas à trouver le PMF, alors que l’application fonctionnait et délivrait les services attendus. La plupart des gens qui ont téléchargé Knomee n’ont simplement pas compris ni comme elle fonctionnait, ni à quoi elle servait. Il m’a semblé intéressant de faire un petit post-mortem, avec les biais évidents du développeur principal, mais aussi avec le bénéfice du recul, puis que la constatation de l’échec date de 2020. Je partage cette anatomie d’un échec parce qu’elle résonne à la fois avec des échecs que j’ai vu sur d’autres applications ou services auxquels j’ai participé, et également parce que les autres startups nées entre 2013 et 2018 sur le même UVP (Unique Value proposition) que Knomee ont également échoué.
Ce billet est organisé comme suit. La section 2 rappelle brièvement l’objectif de l’application Knomee et son histoire de 2015 à 2019. Une fois passée une brève période de marketing digital qui a permis à l’application d’émerger, il est apparu que l’application ne rencontrait pas l’usage attendu. Nous allons donner les principales raisons qui touchent à l’ergonomie et la qualité de l’application, mais également à la complexité de la promesse (UVP). La section 3 approfondit les raisons de cet échec et essaye de tirer des enseignements plus généraux qui recoupent l’expérience de l’auteur autour d’autres applications mobiles ou services digitaux. La section 4 donne un peu plus de contexte sur mes convictions personnelles autour du domaine du self-tracking et explique de la sorte pourquoi l’application est toujours disponible. 2023 a été l’occasion de faire un pivot vers une forte simplification pour conserver le cœur des fonctionnalités avec un effort minimal, en attendant un développement plus visible de la médecine 4P (préventive, prédictive, précise/personnalisée et participative).
2. Anatomie d’un Échec
L’application Knomee est une application de self-tracking :
- Qui mélange des données automatiques issues du téléphone, de sa montre ou de tout autre objet connecté intégré via HealthKit (le framework fournit par Apple qui nourrit l’application « Santé » présente sur les iPhones) … et des données qualitatives rentrées par l’utilisateur.
- Son design est optimisé pour minimiser le temps de tracking, tout se fait avec le pouce et des sliders (boutons rond glissant).
- Elle est entièrement configurable : on peut tracker ce que l’on veut => c’est en fait un éditeur de self-trackers (une fonctionnalité très puissante mais qui ne sert à personne hormis l’auteur de ces lignes).
- Elle est orientée autour de petits groupes de trackers associé à des efforts/habitudes en vue d’un objectif. L’illustration ci-jointe montre un objectif de maximiser son énergie (qualitatif) à partie de son sommeil, du nombre de pas et de son taux d’oxygène dans le sang (ici 3 paramètres fournis par HealthKit).
- Ces groupes de trackers sont appelés « quêtes » car ils correspondent à des hypothèses causales, qui postulent que l’on peut améliorer un élément de santé ou de bien-être en agissant sur quelques pratiques. Le premier nom de Knomee était « IsItWorthIt ?», puisque le self-tracking est une façon de valider si un certain type d’efforts apporte les bénéfices escomptés


L’histoire de Knomee s’échelonne sur 10 ans. La première année (2015) a été un année de formation : cours de Oussama Amar (MooC Koudetat), diverses lectures et beaucoup de formation sur le développement iPhone (excellent cours en ligne de Stanford). Il nous a fallu deux ans pour faire émerger un produit sur l’App Store, suivi de deux ans de développement de versions successives au travers des feedbacks des premiers utilisateurs. Après une période de recherche assez intense sur la recherche de la causalité dans des ensemble de time-series, le constat de l’échec a été fait et nous sommes passés en mode « frigo » en 2021-2022, suivi par un pivot de simplification agressif fin 2023, ou Knomee a été débarrassée de tous les algorithmes complexes pour ne garder que des traitements statistiques simples.
Constater l’échec a été assez simple : avec une effort raisonnable de Marketing digital autour du site Web et de deux comptes sur les réseaux sociaux, nous avons réussi à obtenir une centaine d’utilisateurs pendant environ deux ans, mais avec un taux très fort d’abandon. Chaque mois, une nouvelle cohorte remplaçait la précédente qui s’était lassée. Comme je l’ai dit plus haut, mon analyse est forcément biaisée mais je vous livre néanmoins les sept causes principales de cet échec :
- Une expérience utilisateur (incluant l’interface) trop difficile à comprendre et à découvrir.
- Des problèmes de stabilité de l’application, surtout les deux premières années, qui ne sont pas acceptables dans le monde d’aujourd’hui.
- La valeur de la promesse se délivre dans la durée et cet UVP était donc mal qualifié.
- Une erreur de méthode avec des MVP trop gros et pas assez de retour des utilisateurs.
- Un marketing digital naïf qui n’a pas permis de toucher les ambassadeurs/prescripteurs.
- Un sujet évident de timing : il y a eu une bulle « quantified self » qui a éclaté au moment où Knomee devenait disponible.
- La complexité du domaine « comprendre les chaines causales dans une approche de self-discovery »
Le sujet de l’expérience utilisateur est fascinant : tous les utilisateurs avec qui nous avons fait une prise en main personnalisée ont compris rapidement et en profondeur comment l’application fonctionnait, tous ceux à qui nous avons envoyé un lien et un petit mode d’emploi se sont perdus et découragés. Nous allons y revenir dans la section suivante car le dilemme était évident depuis le départ : une application très simple (en 2015 il y avait foison d’application de self-tracking sur le AppStore) apporte peu de valeur et les utilisateurs se lassent vite, mais chaque couche de richesse fonctionnelle éloigne une fraction importante de ces même utilisateurs.
Comme cela a été dit, Knomee a été conçue comme une expérience de projet entrepreneurial, avec un budget temps de développement de quelques dizaines d’heure par an. C’est beaucoup si l’on exploite bien la puissance de la plateforme iOS/XCode, mais c’est peu pour profiter de la richesse des outils de mise au point et de surveillance de l’usage ou des défauts. De façon très classique nous sommes tombés dans le piège du « feature creep » et les MVP sont rapidement devenus tout sauf minimaux. Au début nous étions assez rigoureux et le design des sliders actionnables avec le pouce est le résultat de nombreuses itérations courtes pour réduire efficacement le temps de capture. Ensuite, nous avons beaucoup cherché à faire de Knomee un produit pour coach/ambassadeur (avec l’idée que le coach définit un scénario de self-tracking et envoie l’objet « quête » par email à ses patients/équipiers), mais sans mettre en place la boucle CFLL (Customer Feedback Learning Loop) dont je parle constamment dans mes interventions … pour une bonne raison : j’ai vu sur de nombreux services digitaux ce qui se passe lorsque cette boucle CFLL ne fonctionne pas.
La figure suivante donne l’historique de l’intérêt pour « quantified self » sur Google Trends. Elle se passe presque de commentaire : l’idée de Knomee a germée à une époque ou les idées de l’UVP « étaient dans l’air du temps », mais ce temps a rapidement passé. Il a été dit que le «quantified self » était destinée à une petite population à l’intersection des « narcissistes » et des « analytiques compulsifs » et il y a peut-être une part de vérité. L’autre figure est associée au terme « self tracking » et montre une persévérance plus forte … l’exemple de « sleep tracking » montre même une augmentation régulière, de même que « energy tracking » qui est également un sujet qui émerge.
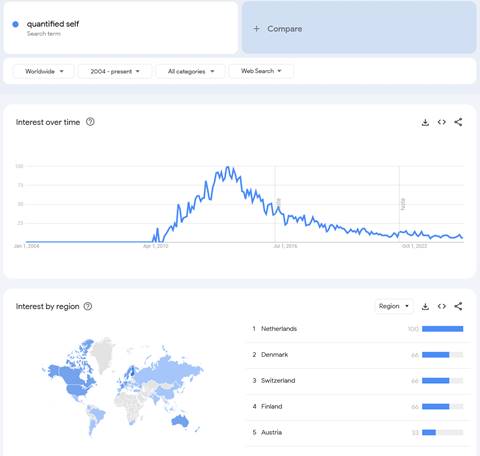
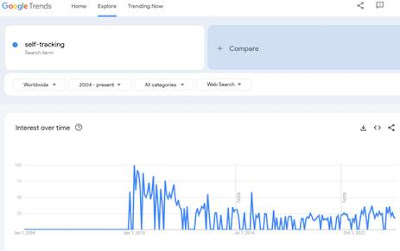
Ces figures permettent de trouver une explication aux deux observations suivantes :
- Toutes les startups qui étaient en compétition avec Knomee ont disparu. On peut distinguer trois groupes : (a) la majorité se sont positionnées sur le self-tracking avec des applications très simples pour tracker des tas de choses, de façon spécialisée (sommeil, activité, humeur, etc.). Ces applications n’apportent pas de valeur unique, elles ont eu une durée de vie très courte ; (b) le petit groupe « tracking & data science », dont Knomee faisait partie : la complexité de la value proposition, de l’expérience de l’app, et le temps qu’il faut pour véritablement tirer de la valeur les ont empêché de trouver le PMF – comme l’objectif était de créer de la différentiation par les algorithmes, ces startups ont duré un peu plus longtemps; (c) les applications qui ont compris qu’il fallait ajouter un vrai feedback enrichi au self-tracking et ont proposé de le faire avec un coach : elles ont également disparu parce que le business model ne tient pas (en attendant que les LLM le fassent, ce qui est probablement la prochaine rupture du domaine).
- En 2016, mes collègues de la Silicon Valley m’ont dit : « arrêtes Knomee, Facebook et Apple sont dessus, ils ont publié leurs stratégies et ils investissement massivement en IA pour le coaching de la santé ». C’était tout à fait exact (et je suis allé lire ces stratégies avec intérêt), mais pour l’instant, en tant qu’utilisateur, je n’ai rien vu. Cela montre, de mon point de vue, que cet UVP est difficile à réaliser (le point 7 de ma liste).
Notons que les heureux utilisateurs des objets connectés Withings, dont je fais partie, ont à leur disposition une application qui apporte une partie de ces fonctionnalités « self-tracking with sense », et qui ne fait que progresser depuis 10 ans (et qui est beaucoup plus riche que l’application Santé d’Apple, qui elle aussi a beaucoup progressé). Il serait logique de « bazarder Knomee » en attendant que Withings ou Apple fasse le job, mais on en est encore très loin. Aucune de ces apps ne permet le self-tracking qualitatif, ni ne fournit de cadre pour une analyse causale multifactorielle. On verra dans la section 4 que c’est pourtant le cœur de la création de valeur autour du self-tracking, avec une véritable personnalisation.
3. Analyse des causes profondes
- Un trop faible nombre d’interviews d’utilisateurs, et surtout trop centrés au début du développement de l’UX Knomee. Pour paraphraser Kevin Kelly, pour une application qui s’appuie sur des fonctionnalités avancées (du type insights issus de l’IA), une bonne UX est cultivée et non pas conçue (« grown, not designed »). Toutes les métriques embarquées ne remplacent pas les entretiens avec les utilisateurs (Ash Maurya). Pour surmonter toutes les difficultés qu’amènent une expérience riche, il faut pouvoir tirer parti des bénéfices de l’amélioration continue.
- L’avis des utilisateur sur l’interface utilisateur (UI) est en fait positif, les qualités artistiques de notre designer sont visibles d’un bout à l’autre de l’applications. Mais un design élégant n’est pas la même chose qu’un design simple d’emploi. L’ « usabilité » de l’interface est une science, elle s’appuie sur l’expérience, ce que nous n’avions pas dans l’équipe.
- Un des aspects les plus importants du UX design est l’on-boarding, la partie de l’expérience qui consiste à faire découvrir à l’utilisateur la finalité de l’application, l’UVP dont il va pouvoir bénéficier. Nous savions dès le départ que c’était un défi puisque, comme je le raconte dans mon livre, mon expérience des années précédentes m’avait montré que la première cause des échecs des services numériques n’est pas un service qui ne fonctionne pas, mais simplement un service dont l’utilisateur n’a pas compris l’existence. Pour réussir l’onboarding d’une application complexe, il faut concevoir cet UX comme un jeu de découverte, en convoquant les principes du « Emotional Design » de Don Norman, en alternant des temps forts et des temps faibles, en offrant des « récompenses » le long du chemin d’apprentissage. Nous avons bien essayé d’appliquer ces principes, mais nous avons échoué à le faire de façon simple.
- La promesse de Knomee est une promesse éminemment personnalisée : il faut pouvoir choisir ce que l’on mesure, pourquoi (quelle « quête »), de quelle façon, à quelle fréquence. Nous avons fait dès le départ des choix drastiques en matière de respect des données personnelles et nous avons développé une couche technologique importante pour adapter l’expérience et les explications « inApp » au contexte dynamique de l’utilisateur (ces explications varient en fonction du contexte et de l’expérience), mais cela n’a pas suffi, par manque de co-design avec les utilisateurs et surtout parce que le « on boarding » n’a pas été inclus dans une CFLL.
- Mon manque d’expérience dans le domaine des applications mobiles (et je parle d’expérience concrète, vu que j’avais géré des équipes de développement mobile depuis 10 ans). Les MOOC et les cours en lignes, les tutos YouTube et StackOverflow c’est bien, mais cela ne remplace pas « les heures de vols ».
- Le mode « expérience en vraie grandeur » : nous avions pris dès le départ la décision de nous concentrer sur une plateforme (ici iOS) en attendant de voir si nous trouvions un PMF (une bonne décision tirée de mes expériences passées), mais le budget temps global est resté limité, ce qui ralentit l’acquisition d’expérience (cf. le point précédent, ou cf. les leçons de Oussama Amar).
- La mauvaise utilisation des outils de diagnostic (type Crashlytics) – qui a ralentit la vitesse des boucles d’investigations sur les bugs reportés, et en particulier les crashs (application qui quitte soudainement) qui ne sont pas acceptables dans le paysage encombré d’aujourd’hui.
4. Pourquoi Knomee est toujours disponible sur l’AppStore ?
- L’histoire de Knomee a en fait commencé plusieurs années auparavant. A partir de 2009 j’ai commencé à faire des malaises vagaux, en particulier en faisant du sport. J’ai commencé à intuiter que mon alimentation jouait un rôle dans la survenue de ces malaises, et j’ai appliqué la méthode « Benjamin Franklin » avec un Excel pour les automesures et mon PC pour l’analyse statistique. L’analyse des données a tout de suite confirmé ce qui n’était qu’une intuition, et donné un peu de poids à cette hypothèse fantaisiste (grosse incompréhension pendant les tests d’effort lorsque j’expliquais que je courrais à jeun sans problème, mais pas avec un petit déjeuner, tandis que l’avis unanime était que c’était un problème d’hypoglycémie). Cela m’a permis de mettre cette (ennuyeuse) condition sous contrôle, face au scepticisme complet de mes médecins (hormis mon cardiologue). En 2019, une opération de la valve mitrale a éradiqué cette condition d’hyper sensibilité (en particulier au gluten) – ce qui est un petit mystère en soi.
- J’ai utilisé Knomee à une époque où j’avais du mal à dormir et j’étais persuadé que les cafés trop nombreux étaient une des causes. En fait l’analyse causale des données a indiqué l’inverse (je buvais plus de cafés parce que j’étais fatigué) et Knomee m’a permis de m’orienter dans une meilleure direction (je passe ici le fait que, dans le cadre de Knomee, j’ai lu des milliers de pages sur ce que la science nous dit sur comment mieux dormir, avoir plus d’énergie, maitriser son poids, prendre soin de son cœur, etc.)
- L’utilisation de la montre Apple Watch et du self-tracking associé m’ont permis de valider la pertinence – et de régler – le « intermittent fasting » pour mon métabolisme. Dans ce dernier cas, le bénéfice en termes de bien être et de meilleure santé (validée par les analyses de sang) est en premier lieu attribuable à la montre comme sources de données, mais Knomee m’a aidé à comprendre le schéma systémique dont je vais parler plus bas.
La seconde raison, au contraire, est écosystémique : le self-tracking automatique de notre corps ne fait qu’augmenter parce que tous nos objets connectés s’enrichissent constamment de nouveaux capteurs et de nouvelles capacité d’analyse des trackers existants. C’est évident si vous avez une Apple Watch (personnellement, je ne pourrais pas me passer de Knomee pour tirer parti des data fournies pas ma montre), mais c’est déjà le cas si vous avez « simplement » un iPhone. Depuis le début de Knomee, l’arrivée du capteur d’oxygénation du sang m’a permis à la fois de mieux surveiller et contrôler mon asthme, tandis que l’arrivée du HRV (Heart Rate Variability) – et du VOP (Velocity of Pulse) sur ma balance Withings – me donne des insights très utiles à la fois sur ma santé cardiaque et comment en prendre soin. Mon intuition, dont l’avenir dira si elle est juste, est que plus nous disposons de ce jumeau numérique de notre corps, plus le tracking subjectif et qualitatif est utile pour former un corpus complet de données qui permet de trouver du sens (une fois de plus, « self-tracking with sense »).
 La troisième raison est la croissance de la connaissance scientifique sur l’importance de notre style de vie et nos habitudes sur notre santé et notre longévité. C’est, d’une certaine façon, un pied de nez aux courbes de Google Trends citée plus haut : plus le temps passe plus nous savons avec certitude que « taking good care of our bodies is worth it ». A titre d’exemple, je cite ici le best-seller de Peter Attia, « Outlive : the science and art of longevity », dont la principale promesse est de décrire les bonnes règles de vie et d’hygiène de comportement à adopter entre 40 et 60 ans pour mieux vivre à 80 ans. L’ambition de la médecine 4P (Personalised, preventive, predictive, participatory) va progressivement s’imposer par son efficacité et l’UVP de Knomee (self-tracking with sense) est forcément amenée à trouver un jour, sous d’autres formes, une nouvelle jeunesse. Comme je l’ai dit plus haut, il existe des centaines de livres sur le sujet, mais je recommande celui de Peter Attia, à la fois à cause de l’importance de sa bibliographie scientifique et à cause de son ton pragmatique et concret. Mais la lecture ne suffit pas : l’intérêt de l’appoche « self-tracking » est de découvrir la dimension « Personalized » de la médecine 4P et d’approcher par l’expérience ce qui « fonctionne pour vous ». Une application comme Knomee permet de poser des hypothèses causales (par exemple après la lecture d’un livre) et de voir comment elles fonctionnent pour vous. L’utilisation répétée de cette approche conduit à construire des réseaux de «quêtes », qui sont des représentations systémiques (cercles de renforcement) des « bonnes pratiques » qui vous conviennent.
La troisième raison est la croissance de la connaissance scientifique sur l’importance de notre style de vie et nos habitudes sur notre santé et notre longévité. C’est, d’une certaine façon, un pied de nez aux courbes de Google Trends citée plus haut : plus le temps passe plus nous savons avec certitude que « taking good care of our bodies is worth it ». A titre d’exemple, je cite ici le best-seller de Peter Attia, « Outlive : the science and art of longevity », dont la principale promesse est de décrire les bonnes règles de vie et d’hygiène de comportement à adopter entre 40 et 60 ans pour mieux vivre à 80 ans. L’ambition de la médecine 4P (Personalised, preventive, predictive, participatory) va progressivement s’imposer par son efficacité et l’UVP de Knomee (self-tracking with sense) est forcément amenée à trouver un jour, sous d’autres formes, une nouvelle jeunesse. Comme je l’ai dit plus haut, il existe des centaines de livres sur le sujet, mais je recommande celui de Peter Attia, à la fois à cause de l’importance de sa bibliographie scientifique et à cause de son ton pragmatique et concret. Mais la lecture ne suffit pas : l’intérêt de l’appoche « self-tracking » est de découvrir la dimension « Personalized » de la médecine 4P et d’approcher par l’expérience ce qui « fonctionne pour vous ». Une application comme Knomee permet de poser des hypothèses causales (par exemple après la lecture d’un livre) et de voir comment elles fonctionnent pour vous. L’utilisation répétée de cette approche conduit à construire des réseaux de «quêtes », qui sont des représentations systémiques (cercles de renforcement) des « bonnes pratiques » qui vous conviennent.
Pour finir, je vais évoquer brièvement le « pivot » de fin 2023, qui a essentiellement consisté à alléger Knomee pour que sa maintenance devienne une tâche légère, commensurée avec les bénéfices que l’application m’apporte aujourd’hui. La décision principale a été d’abandonner le moteur de Machine Learning (EMLA : Evolutionary Machine Learning Agents), qui est un superbe exemple de techno-push et dont l’histoire se trouve dans la présentation que j’ai faite en 2019 à ROADEF. Je n’utilise maintenant que des algorithmes statistiques simples, et cela a également conduit à simplifier l’interface utilisateur. Une fois ce pivot effectué, Knomee est construite autour de deux UVP :
- Faire du self-tracking la tâche la plus simple et plus rapide possible (je ne cherche plus à convaincre qui que ce soit que c’est une bonne idée).
- Tirer le meilleur parti de mon Apple Watch (un sujet qui s’enrichit constamment), en particulier lorsque je vais nager (il n’y a plus rien à faire sur le running ou le biking, il existe des tonnes d’excellentes apps, mais le swimming est moins bien couvert)
J’ai conservé à l’application ses capacités de data-visualisation (par exemple l’analyse chronologique et géospatiale des données collectées parce que c’est à la fois amusant et instructif). La seule nouvelle capacité ajoutée à la version 3 est l’assistance pour découvrir les « quêtes intéressantes » en proposant des assemblages de trackers pertinents, pour construire progressivement les « quest networks » évoqué plus haut (l’ironie de ce dernier point ne m’échappe pas : après avoir reconnu que le concept de « quête » comme unité élémentaire self-découverte causale était trop abscons pour les utilisateurs de Knomee, il est évident que celui de réseau causal systémique n’a pas la moindre chance de trouver un PMF).
5. Conclusion
Je vais conclure ce billet en résumant les trois idées principales qui émergent de cette anatomie d’un échec :
- La conception de l’expérience utilisateur est la pierre angulaire d’un service innovant et la première cause des échecs. Ash Maurya nous a dit : le MVP est ce qui délivre l’UVP à l’utilisateur, mais cela commence par le fait que l’utilisateur comprennent et accepte la promesse de l’UVP.
- Il faut parler à ses utilisateurs de façon répétée pour apprendre d’eux. Dans un monde où les possibilités de la technologie sont sans limites, la tentative du techno-push est grande et il faut s’astreindre à une approche tirée (pull) par l’observation et les retours des utilisateurs.
- L’approche « bootstrapping », consistant à démarrer son projet entrepreneurial avec les moyens dont on dispose sans lever de capital pour garder la liberté de son rythme a plein d’avantages, illustrés par les principes de l’effectuation. Elle a aussi ses limites, et il faut avoir l’humilité de les comprendre pour les contourner.
Je vais conclure par une méta-analyse : si Knomee est un échec en tant qu’application mobile, l’expérience de se lancer dans une aventure de développement d’un service digital « le plus sérieusement possible » est, avec 10 ans de recul, un véritable succès :
- forts progrès sur la compréhension de ce qu’est le développement mobile … et l’utilisation de Stack Overflow,
- progrès sur la compréhension du Lean startup et des best practices,
- le très grand nombre de lectures que j’ai pu faire sur les sujet de la médecine 4P, des hygiènes de vie et de la santé en général m’ont été directement bénéfiques,
- d’autres bénéfices, pour les autres membres de la micro-équipe Knomee, sur le plan personnel et professionnel, qui n’ont pas vocation à être partagés.